
سوگیری الگوریتمی چیست؟ تعریف، مثالها، انواع تبعیض و 12 راهکار کاهش Bias
سوگیری الگوریتمی چیست و چرا در عصر تصمیمگیریهای خودکار اینهمه مهم شده است؟ سوگیری الگوریتمی زمانی رخ میدهد که خروجی یک مدل یا سیستم هوش مصنوعی بهصورت نظاممند و تکرارشونده به نفع یا ضرر گروههایی از افراد تغییر کند؛ حتی وقتی دقت کلی مدل بالا به نظر میرسد. ریشهی این مسئله معمولاً در ترکیبی از تعریف نادرست هدف پیشبینی، دادههای نامتوازن، متغیرهای جانشین (Proxy) و شیوهی استقرار نادقیق نهفته است. نتیجه؟ تصمیمهایی که میتواند بر استخدام، اعطای وام، سلامت، آموزش و حتی قیمتگذاری پویا اثر بگذارد. در این راهنمای عملی، با زبانی روشن توضیح میدهیم سوگیری الگوریتمی (Algorithmic Bias) چگونه شکل میگیرد، چه انواعی دارد (از Disparate Treatment تا Disparate Impact) و با چه متریکها و چکلیستهایی میتوان آن را اندازهگیری، ممیزی و کاهش داد. هدف ما صرفاً تعریف مفاهیم نیست؛ میخواهیم نشان دهیم چگونه میتوان عدالت الگوریتمی را از مرحلهی طراحی تا پایش پس از استقرار، به فرآیندی استاندارد و قابل پیگیری تبدیل کرد تا تصمیمهای خودکار، منصفانه، قابل توضیح و قابل اعتماد باشند.
سوگیری الگوریتمی چیست؟
تعریف عملیاتی و تمایز با خطای تصادفی
تعریف عملیاتی (Exact definition):
«سوگیری الگوریتمی» زمانی رخ میدهد که یک سامانهٔ تصمیمیار (مدل یادگیری ماشین، سیستم رتبهبندی یا قاعدهٔ مبتنی بر داده) بهطور نظاممند، تکرارشونده و گروهمحور خروجیهایی تولید کند که برای یک یا چند گروه جمعیتی نامتوازن است—حتی اگر دقت میانگین مدل بالا به نظر برسد. به بیان اجرایی، هرگاه احتمال پذیرش/رد، امتیازدهی یا تخصیص منبع برای یک گروه، پس از کنترل عوامل مرتبط با شایستگی/ریسک، بهطور پایدار از گروه مرجع منحرف بماند، با Bias روبهرو هستیم نه صرفاً خطای معمول.
نشانههای میدانیِ Bias (قابل سنجش):
-
اختلاف پایدار در نرخهای کلیدی بین گروهها (مثلاً تفاوت معنادار در TPR/FPR یا نرخ پذیرش)، که در بازههای زمانی و زیرنمونههای مختلف تکرار میشود.
-
باقیبودن شکاف عملکرد بعد از کنترل متغیرهای غیرحساس (شدت نیاز، سابقهٔ معتبر، نسبت بدهی و…)، نشاندهندهٔ اثر متغیرهای جانشین (Proxy) یا تعریف نادرست هدف است.
-
بازتولید همین الگو هنگام انتقال مدل به محیطهای نزدیک (در حضور Drift قابل کنترل)؛ یعنی انحراف ساختاری نه رویدادی.
تمایز علمی با «Noise» (خطای تصادفی):
-
Noise پراکندگی بیجهت و کوتاهمدت است؛ با دادهٔ بیشتر، میانگینگیری و تکرار آزمایش معمولاً کاهش مییابد و جهت ثابتی ندارد.
-
Bias انحراف جهتدار و سیستماتیک است؛ در طول زمان پایدار میماند و بدون مداخلهٔ ساختاری از بین نمیرود (بازتعریف هدف تصمیم، بازتوزین داده، مهار پروکسیها، قیود انصاف مانند Equal Opportunity/Equalized Odds، کالیبراسیون درونگروهی).
مثال جمعوجور برای تفکیک Bias از Noise (غیرکپی):
اگر مدل ارزیابی وام بهجای «ریسک نکول واقعی»، با «هزینهٔ تاریخی استفاده از خدمات مالی» آموزش ببیند، گروههای کمبرخوردار—به دلیل دسترسی تاریخی کمتر—بهطور سیستماتیک امتیاز اعتبار پایینتری میگیرند، حتی با توان بازپرداخت یکسان. این Bias است (جهتدار و تکراری). اما اگر یک هفته بهدلیل دادهٔ کم چند پروندهٔ خوب اشتباه رد شود و با افزایش داده برطرف گردد، این Noise است.
نکتهٔ سئو (LSI بدون کیورداستافینگ):
در متنِ این بخش از عبارتهای طبیعیِ هممعنا استفاده کنید: «تعریف سوگیری الگوریتمی»، «Algorithmic Bias یعنی چه»، «انحراف نظاممند مدل»، «عدالت الگوریتمی». حضور عبارت اصلی در H2 و پاراگراف آغازین کافی است؛ تمرکز بر خوانایی و نیت جستجو.
دوره پیشنهادی

صفر تا صد راه اندازی استارت آپ با هوش مصنوعی (گادمود)
چرا این پدیده اهمیت دارد؟
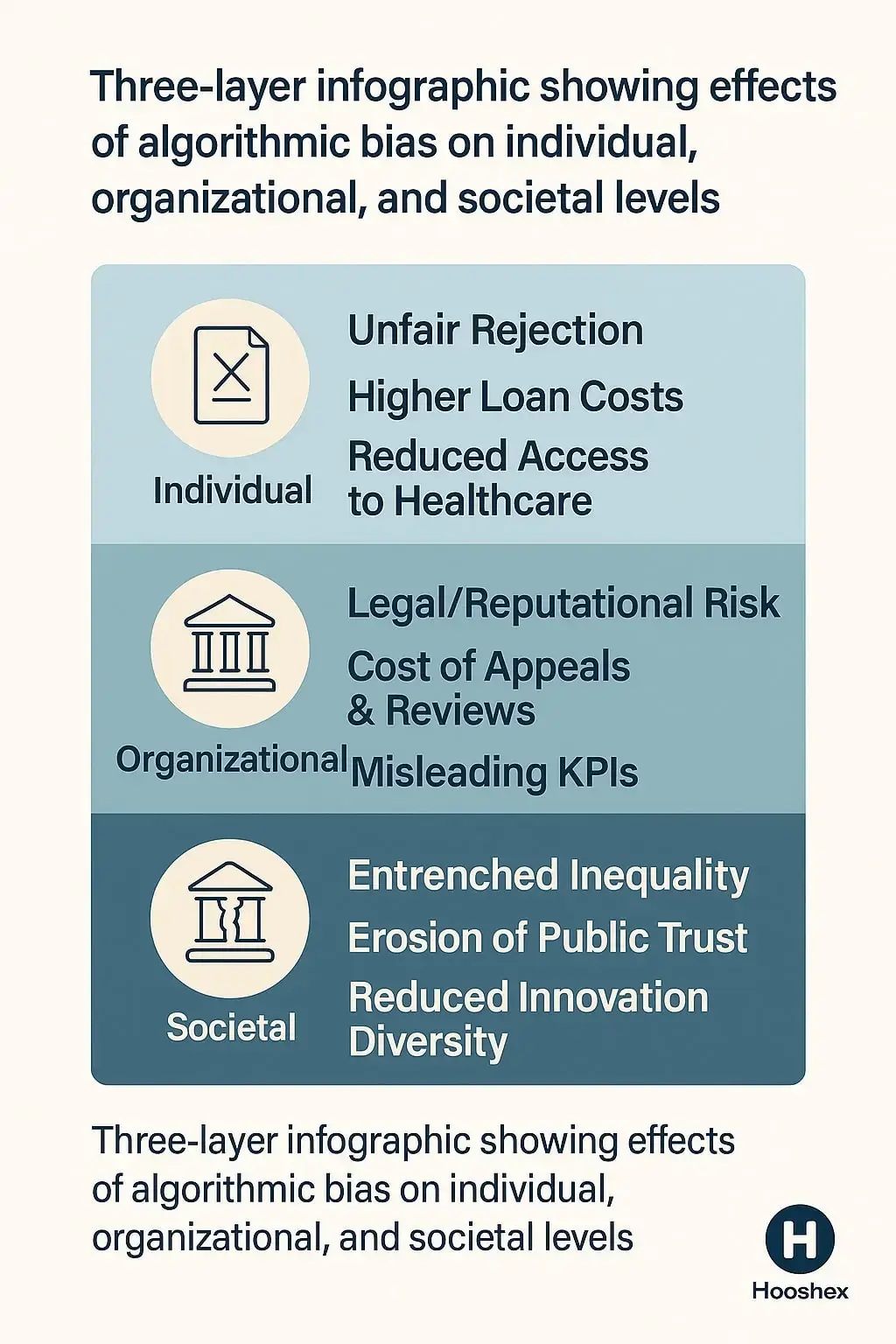
۱) پیامدهای فردی (انسانمحور):
-
فرصتهای ناعادلانه: رد رزومه، امتیاز اعتباری کمتر، سقف دسترسی پایینتر به خدمات درمانی/آموزشی برای افراد همسطح از نظر شایستگی.
-
برچسبزنی و خودتحققبخشی نابرابر: اگر سامانه مرتباً یک گروه را کمصلاحیت نشان دهد، مسیرهای رشد و اعتمادبهنفس نیز بهتدریج محدود میشود.
-
اثر آبشاری بر رفاه: تصمیم بدِ امروز در وام/استخدام، فردا خود را در مسکن، پس انداز و سلامت نشان میدهد.
۲) پیامدهای سازمانی (حاکمیت و ریسک):
-
ریسک حقوقی/انطباقی: مواجهه با دعاوی تبعیض، جریمهٔ مقرراتی، الزام به اصلاح فوری سامانهها.
-
ریسک اعتباری و برند: از دست دادن اعتماد مشتریان/کاربران، پوشش رسانهای منفی، فرار استعدادها.
-
هزینههای پنهان عملیاتی: افزایش خطاهای پرهزینه، بار اعتراضات/بازبینی، نیاز به اصلاحات اضطراری پس از استقرار.
-
کژتنظیمی اهداف: استفاده از سیگنالهای جانشین (Proxy) بهجای متغیرهای واقعیِ تصمیم باعث میشود KPIها «به ظاهر» بهبود یابند اما کیفیت تصمیم بدتر شود.
۳) پیامدهای اجتماعی (عدالت و پایداری):
-
تداوم نابرابری ساختاری: الگوریتمها میتوانند تبعیضهای تاریخی را تثبیت و تسریع کنند.
-
گسست اعتماد عمومی به فناوری و نهادها: وقتی مردم اثرات ناعادلانه را میبینند اما توضیح شفافی دریافت نمیکنند، سرمایهٔ اجتماعی کاهش مییابد.
-
اثر شبکهای بر نوآوری و رقابت: حذف سیستماتیک برخی گروهها از وام/تحصیل/شغل، اکوسیستم نوآوری را کوچکتر و کمتنوعتر میکند.
چگونه این اهمیت را عملیاتی کنیم؟ (چکلیست کوتاه برای مدیران/تیمها)
-
همراستاسازی هدف پیشبینی با هدف تصمیم (Risk در برابر Cost).
-
تعریف گروههای مقایسه و متریکهای انصاف متناسب با دامنه (DP/EO/EOdds/Calibration).
-
ممیزی دورهای پس از استقرار (Monitoring بههمراه آستانههای هشدار برونخطری).
-
سیاست «حق توضیح و اعتراض» برای کاربر و مسیر روشن تصحیح.
-
ثبت و مستندسازی (Model/Data Cards) برای پاسخگویی و بازبینی مستقل.
انواع سوگیری
تبعیض مستقیم و غیرمستقیم (Disparate Treatment vs Disparate Impact)
تبعیض مستقیم (Disparate Treatment):
وقتی تصمیم یا توصیهٔ الگوریتمی بهطور صریح بر پایهٔ یک ویژگی محافظتشده (مثل جنسیت، قومیت، سن، ناتوانی) فرق بگذارد.
مثال کوتاه: موتور گزینش رزومه اگر بهطور مستقیم «زن بودن» را امتیاز منفی بدهد، با تبعیض مستقیم طرفیم—even اگر مدل در مجموع دقت بالایی داشته باشد. این شکل از تبعیض الگوریتمی ماهیتاً غیرقانونی/غیراخلاقی است و با «پنهانسازی» ویژگی حساس حل نمیشود.
تبعیض غیرمستقیم (Disparate Impact):
وقتی سیاست ظاهراً بیطرف یا ویژگیهای غیرحساس، اثر نابرابر بر یک گروه بگذارند.
مثال کوتاه: شرط «سابقهٔ کاری در ۱۰ شرکت برتر» ممکن است بهطور سیستماتیک گروههای کمبرخوردار را حذف کند، حتی اگر «نام شرکت» ظاهراً ویژگی حساسی نباشد. اینجا اثر نابرابر از طریق متغیرهای جانشین (Proxy) رخ میدهد و با تستهای اختلاف عملکرد گروهی باید آشکار و اصلاح شود.
سیگنالهای E-E-A-T: تعریفهای دقیق و پذیرفتهشدهٔ مفهومی، تمایز روشن Treatment/Impact، نمونههای عملی.
نکتهٔ سئو: استفادهٔ طبیعی از عبارات هممعنا مثل «تبعیض الگوریتمی»، «اثر نابرابر»، و اشارهٔ ضمنی به پرسش کاربر دربارهٔ «سوگیری الگوریتمی چیست» بدون کیورد استافینگ.
سوگیریهای داده/مدل/استقرار در ساخت هوش مصنوعی
در چرخهٔ عمر یک سیستم، ریسک Bias فقط در «دادهٔ آموزش» نیست؛ از تعریف مسئله تا پایش پس از استقرار امتداد دارد. جدول زیر یک طبقهبندی تخصصی + نسخهٔ عملی سریع ارائه میدهد:
| نوع سوگیری | منشأ (کجا شکل میگیرد؟) | نشانهها/هشدارها | راهکار فوری (Actionable) |
|---|---|---|---|
| Representation Bias | گردآوری داده؛ کمنمایی/بینمایی برخی گروهها | افت معنادار TPR/Precision برای گروههای کمنمونه | افزایش نمایندگی هدفمند (oversampling/augmentation)، وزندهی کلاسها، جمعآوری دادهٔ تکمیلی |
| Measurement Bias | اندازهگیری نابرابر متغیرها/لیبلها بین گروهها | اختلاف پایدار بین خروجی و واقعیت در گروه خاص | همسانسازی ابزار سنجش، بازبرچسبگذاری کنترلشده، استفاده از متغیرهای جایگزین معتبر |
| Selection Bias | روش نمونهگیری/کانال ورودی کاربران | عملکرد خوب در دادهٔ داخلی و افت شدید در دادهٔ میدانی | بازنمونهگیری تطبیقی، تقسیمبندی منصفانهٔ train/validation، تست بر مجموعههای بیرونی |
| Historical Bias | تاریخ داده و قواعد سازمانی پیشین | بازتولید تبعیضهای قدیمی در خروجیهای جدید | بازتعریف هدف تصمیم (Objective) و پاکسازی قواعد تاریخی، ارزیابی اثر (AIA) پیش از استقرار |
| Proxy Bias | ویژگیهای ظاهراً غیرحساس که نقش جانشین دارند (کدپستی، نوع دستگاه، ساعت استفاده) | باقیماندن شکاف بعد از حذف ویژگیهای حساس | تحلیل اهمیت ویژگیها + تست حذف/جایگزینی، محدودسازی یا نویزگذاری روی پروکسیها |
| Aggregation Bias | مدل واحد برای جمعیتهای ناهمگن | عملکرد میانگین خوب اما شکاف شدید زیرگروهی | مدلهای چندآستانه/چندسگمنت، کالیبراسیون درونگروهی، افزودهکردن تعامل ویژگیها |
| Use/Deployment Bias | کاربرد مدل در مسئلهٔ اشتباه یا تغییر کاربری (Function Creep) | KPI ظاهراً خوب اما نارضایتی/شکایت بالا | همراستاسازی هدف پیشبینی با هدف تصمیم، محدودسازی دامنهٔ استفاده، پایش drift و شکایات |
| Feedback Loop Bias | تقویت خروجیهای پیشین در دادهٔ آینده | تشدید نابرابری با گذشت زمان | تزریق دادهٔ خنثیکننده، سیاستهای ضدچرخه، بازطراحی پاداش/کلاس وزنها |
| Evaluation Bias | متریکهای نادرست برای دامنه | مدل «خوب» در AUC اما ناعادلانه در فرصت | متریکهای انصاف (DP/EO/EOdds/Calibration) بههمراه گزارش تفکیکشدهٔ گروهی |
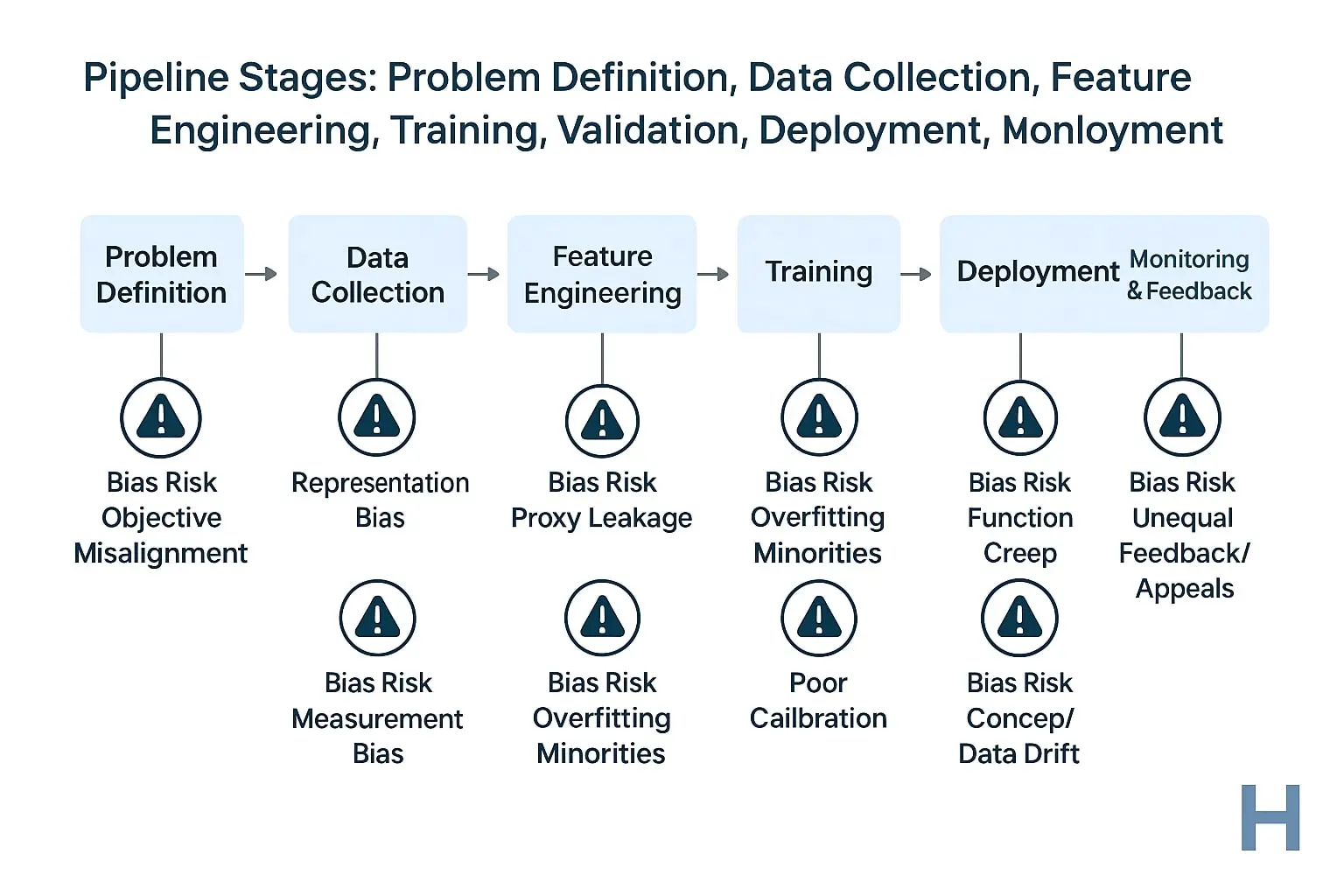
ریشهها در چرخهٔ عمر سیستمِ هوش مصنوعی
برای پاسخ دقیقتر به پرسش «سوگیری الگوریتمی چیست» باید منشأ آن را در کل چرخهٔ عمر مدل ردیابی کنیم: از تعریف مسئله تا استقرار و پایش. در هر گام، معیارهای قابل سنجش و یک SOP کوتاه ارائه شده تا هم E-E-A-T (تجربه، تخصص، اقتدار، اعتماد) تقویت شود و هم اجرای عملی ساده باشد.
1) تعریف مسئله و هدف (Problem & Decision Objective)
ریشهٔ سوگیری: ناهماهنگی بین «هدف پیشبینی» و «هدف تصمیم».
-
نمونهی رایج: پیشبینی Cost بهجای Need/Risk و استفاده از آن برای تخصیص خدمت؛ نتیجه، اثر نابرابر روی گروههای کمبرخوردار.
-
شاخصهای کنترلی: سند «Charter» با تعریف صریح Outcome، واحد اندازهگیری، قیود انصاف (DP/EO/EOdds)، گروههای مقایسه.
SOP کوتاه (قابل اجرا):
-
بنویسید «تصمیم نهایی چیست؟ اثر مطلوب روی کدام جمعیت؟»
-
Outcome را با معیار تصمیم همراستا کنید (مثلاً Need بهجای Cost).
-
از همان ابتدا Success Criteria دوگانه تعیین کنید: دقت + انصاف.
2) داده و ویژگیها (Data & Features)
ریشهٔ سوگیری: پوشش نامتوازن جمعیت و ورود متغیرهای حساس/جانشین (Proxy).
-
نشانهها: کمنمایی گروهها، تفاوت کیفیت اندازهگیری (Measurement Bias)، حضور ویژگیهای جانشین مانند کدپستی/نوع دستگاه/ساعت استفاده.
-
شاخصهای کنترلی: گزارش نمایندگی (Representation Report)، ماتریس همبستگی ویژگیها با گروههای حساس، تست حذف/جایگزینی پروکسیها.
SOP کوتاه:
-
تهیهی Data Card (منشأ، بازهٔ زمانی، حدود خطا، پوشش گروهی).
-
سنجش نمایندگی: حداقل آستانه برای هر گروه (Support ≥ N).
-
غربال پروکسیها: Feature importance + آزمون حذف/نویزگذاری کنترلشده.
-
در صورت نیاز: Oversampling/Weighting هدفمند و جمعآوری دادهٔ تکمیلی.
3) آموزش و اعتبارسنجی (Training & Validation)
ریشهٔ سوگیری: شکاف عملکرد گروهی و overfitting اقلیتها.
-
نشانهها: اختلاف معنادار در TPR/FPR/Precision/Recall بین گروهها، AUC خوب اما Calibration ضعیف درونگروهی.
-
شاخصهای کنترلی: گزارش تفکیکشدهٔ عملکرد (per-group metrics)، آزمون Calibration within Groups، تست پایداری با Splitهای زمانی/جغرافیایی.
SOP کوتاه:
-
افزودن Fairness Constraints یا جریمهٔ Bias در فرایند آموزش.
-
اعتبارسنجی چندبعدی: دقت جهانی + متریکهای انصاف (DP/EO/EOdds).
-
کالیبراسیون درونگروهی و در صورت لزوم آستانههای گروهی کنترلشده با مستندسازی توجیه حقوقی/کسبوکاری.
-
مستند کنید چه مصالحهای بین دقت و انصاف پذیرفته شده و چرا.
4) استقرار و پایش (Deployment & Monitoring)
ریشهٔ سوگیری: Drift (تغییر داده/مفهوم)، Function Creep (تغییر کاربری مدل)، حلقهٔ بازخورد نابرابر.
-
نشانهها: افزایش شکایات/Appeals در گروهی خاص، افت ناگهانی Calibration، جابجایی توزیع ورودیها، استفاده از مدل بیرون از دامنهٔ تعریفشده.
-
شاخصهای کنترلی: داشبورد پایش Drift (Data/Concept), نرخ اعتراض/بازبینی به تفکیک گروه، SLA برای پاسخ به اعتراض، گزارش دورهای «Algorithmic Impact».
SOP کوتاه:
-
تعریف Guardrails: محدودیت دامنهٔ استفاده، حد آستانهٔ ریسک، سیاست «حق توضیح و اعتراض».
-
پایش مداوم: هشدار خودکار برای شکافهای گروهی و افزایش Appeal Rate.
-
بازآموزی/کالیبراسیون برنامهریزیشده بر اساس آستانههای Drift.
-
ممیزی مستقل فصلی + Change Log شفاف (dateModified، نسخهٔ مدل، تغییرات).
چگونه Bias را در انواع هوش مصنوعی بسنجیم؟
اگر میخواهید واقعاً بفهمید «سوگیری الگوریتمی چیست» و آیا در سامانهٔ شما رخ داده، باید آن را اندازهگیری کنید؛ نه با یک عدد کلی، بلکه با مجموعهای از متریکهای عدالت، آزمونهای حساسیت و مقایسهٔ گروهی که قابل تکرار و ممیزی باشند.
متریکهای عدالت و انتخاب آنها بر اساس سناریو
در عمل چهار خانوادهٔ متریک بیشترین کاربرد را دارند. هرکدام «برداشتی از عدالت» را عملیاتی میکند؛ انتخاب نادرست متریک، بهمعنای قضاوت نادرست دربارهٔ عدالت است.
| متریک | تعریف اجرایی (خلاصه) | چه زمانی مناسب است؟ | ریسک/هشدار |
|---|---|---|---|
| Demographic Parity (DP) | احتمال تصمیم مثبت برای همهٔ گروهها تقریباً برابر باشد (P(Ŷ=1 | A=a) ≈ P(Ŷ=1 | A=b)) |
| Equal Opportunity (EO) | نرخ کشف مثبتِ واقعی در گروهها برابر باشد (TPR_a ≈ TPR_b) | سلامت و امنیت؛ از دستندادن افراد نیازمند مهمتر از پذیرش نادرست است (مثلاً غربالگری بیماران پرخطر) | اگر FPR بین گروهها بسیار متفاوت شود، نارضایتی/هزینهٔ اضافی ایجاد میکند |
| Equalized Odds (EOdds) | هم TPR و هم FPR بین گروهها مشابه باشد | استخدام و بسیاری از سناریوهای مقرراتی؛ توازن بین فرصت از دسترفته و پذیرش نادرست | اجرا دشوارتر؛ گاهی به آستانههای تفکیکشده یا پسپردازش نیاز دارد |
| Calibration within Groups | برای همهٔ گروهها، امتیاز پیشبینی احتمال واقعی را درست منعکس کند | اعتبار/وام و نرخگذاری؛ هر «امتیاز ریسک 0.7» باید در هر گروه بهطور مشابه ۷۰٪ ریسک واقعی داشته باشد | با EO/EOdds همیشه همزمان قابل حصول نیست؛ مصالحه لازم است |
راهنمای انتخاب سریع بر اساس دامنه:
-
سلامت: اولویت با EO (کشف عادلانهٔ مثبتهای واقعی) + بررسی کالیبراسیون.
-
استخدام: EOdds برای توازن TPR/FPR بین گروهها + کنترل DP اگر سهم نهایی اهمیت دارد.
-
اعتبار/وام: Calibration within Groups + آستانههای منصفانه؛ در کنار پایش اختلاف TPR/FPR.
-
آموزش/امتحانات: کالیبراسیون و کنترل EOdds برای جلوگیری از نمرهدهی ناعادلانه.
-
پلتفرمهای محتوا/توزیع فرصت: DP برای دسترسی برابر اولیه + سنجههای کیفیت تکمیلی.
ارزیابی اختلاف عملکرد و حساسیت به پروکسیها
فراتر از انتخاب متریک، باید بفهمید چه چیز باعث اختلاف شده است.
۱) نرخها به تفکیک گروه (Per-Group Performance):
-
گزارش گروهبهگروه برای TPR، FPR، Precision، Recall، AUC و Brier Score (برای کالیبراسیون).
-
بازهٔ اطمینان و آزمون معناداری اختلافها (Bootstrap/Permutation) تا از تصادفیبودن فاصله بگیرید.
۲) تحلیل اهمیت ویژگی و همبستگی با گروهها:
-
ترکیب Feature Importance (مثلاً SHAP) با ماتریس همبستگی ویژگیها و متغیرهای حساس/جانشین (کدپستی، نوع دستگاه، ساعت استفاده).
-
یافتن Proxy Features که اثر گروه را منتقل میکنند، حتی اگر خودِ ویژگی حساس حذف شده باشد.
۳) تست حذف/جایگزینی (Ablation & Substitution):
-
سناریوهای «بدون ویژگی X»، «نویزگذاری کنترلشدهٔ X»، یا «جایگزینی X با نسخهٔ امنتر» و مقایسهٔ شکاف عدالت.
-
اگر با حذف/نویزگذاری یک ویژگی، شکاف عدالت بهطور معنادار کاهش یابد، آن ویژگی کاندید پروکسی است.
مثالهای واقعی و درسهای اجرایی
نمونهکاویهای کوتاه و «چکپوینت اجرایی» برای تبدیل سنجهها به عمل—همان چیزی که گوگل در E-E-A-T از «تجربه» و «اقتدار» میخواهد.
سلامت: هزینه بهجای نیاز بالینی
-
مسئله: مدل با «هزینهٔ تاریخی» بهجای «شدت نیاز» آموزش دیده و بیماران کمبرخوردار کمتر شناسایی میشوند.
-
درس اجرایی: بازتعریف هدف (Need نه Cost) + متریک EO برای برابری TPR + کالیبراسیون درونگروهی.
-
چکپوینت: اگر TPR گروهها ±۳٪ اختلاف داشت، بازآموزی/تنظیم آستانه.
استخدام: دادهٔ تاریخی مردانه
-
مسئله: رزومههای موفق تاریخی مردانه بوده؛ مدل بهطور پنهان علیه کلمات/الگوهای زنانه امتیاز میدهد.
-
درس اجرایی: بازتوزین داده، حذف/مهار پروکسیها، ممیزی دورهای با EOdds (TPR/FPR برابر) و گزارش شفاف.
-
چکپوینت: اختلاف TPR یا FPR بیش از ۵٪ → بازطراحی ویژگی یا آستانههای گروهی کنترلشده با توجیه حقوقی.
اعتبار/وام: ریسک در برابر قیمتگذاری رفتاری
-
مسئله: مدل/سیاست نرخ بهره را بر اساس تمایل به پرداخت یا عوامل مکانی تنظیم میکند، نه صرفاً ریسک نکول.
-
درس اجرایی: جداسازی مدل ریسک از قیمتگذاری؛ اجرای Calibration within Groups و سقفهای نرخ منصفانه.
-
چکپوینت: اگر امتیاز 0.7 در گروهها به ریسکهای واقعی متفاوت منجر شد → کالیبراسیون مجدد.
آزمون/آموزش: تکیه بر میانگین مدرسه
-
مسئله: استفاده از «کارنامهٔ تاریخی مدرسه» بهعنوان سیگنال فردی → کاهش نمرهٔ دانشآموزان مدارس کمبرخوردار.
-
درس اجرایی: وزندهی بیشتر به شواهد فردی + کنترل EOdds و گزارش تفکیکشدهٔ خطا.
-
چکپوینت: اختلاف FPR یا TPR بالای ۴٪ → بازنگری ویژگیها و آستانهها.
قیمتگذاری پویا: سقف منصفانه و نظارت
-
مسئله: الگوریتم قیمت را بر مبنای توان پرداخت/محل زندگی بالا میبرد.
-
درس اجرایی: تعیین Ceiling منصفانه، ممیزی DP (نرخ برخورداری برابر از تخفیف/قیمت عادلانه)، لاگبرداری و رسیدگی به اعتراضات.
-
چکپوینت: اگر سهم قیمتهای «بالاتر از سقف منصفانه» در یک گروه >۲٪ از میانگین بود → اقدام اصلاحی فوری.
واژهنامهٔ اصطلاحات
برای پاسخ عملی به پرسش «سوگیری الگوریتمی چیست» لازم است واژهها را دقیق، کوتاه و قابل اجرا تعریف کنیم. این واژهنامه طوری نوشته شده که تیم محصول/دیتا در لحظه بتواند از آن استفاده کند.
-
DP (Demographic Parity) – برابری جمعیتی:
احتمال دریافت تصمیم مثبت برای همهٔ گروهها تقریباً برابر باشد. مناسب برای سناریوهای «توزیع فرصت اولیه». ریسک: ممکن است کارایی را بکاهد اگر شایستگی واقعی بین گروهها متفاوت باشد. -
EO (Equal Opportunity) – فرصت برابر:
نرخ کشف مثبت واقعی (TPR) بین گروهها برابر باشد. اولویت در سلامت/ایمنی؛ از دستندادن موارد واقعی مهمتر است. -
EOdds (Equalized Odds) – برابری شانسها:
هم TPR و هم FPR بین گروهها مشابه باشد. متداول در استخدام و ارزیابیهای مقرراتی؛ توازن بین فرصت از دسترفته و پذیرش نادرست. -
Calibration within Groups – کالیبراسیون درونگروهی:
امتیاز پیشبینی در هر گروه معنای یکسانی داشته باشد (مثلاً ریسک ۰٫۷ واقعاً ~۷۰٪ باشد). ضروری در اعتبارسنجی ریسک (اعتبار/وام). -
Proxy – متغیر جانشین:
ویژگی ظاهراً غیرحساس که رفتار/ترکیب جمعیتی گروه حساس را منتقل میکند (مثل کدپستی بهجای قومیت). تشخیص با تحلیل اهمیت ویژگی و تست حذف/نویزگذاری کنترلشده. -
Function Creep – تغییر خزندهٔ کاربری:
استفاده از مدل خارج از مسئلهٔ تعریفشده (مثلاً تبدیل مدل رتبهبندی به ابزار حذف). منبع رایج سوگیری در استقرار. -
Algorithmic Impact Assessment (AIA) – ارزیابی اثر الگوریتمی:
فرایند مستند برای شناسایی ذینفعان، منافع/مخاطرت، متریکهای انصاف، و طرح پایش قبل و بعد از استقرار. ستون پاسخگویی و اعتماد. -
Representation/Measurement/Selection/Historical Bias – سوگیریهای نمایندگی/اندازهگیری/انتخاب/تاریخی:
چهار منشأ دادهمحورِ رایج: کمنمایی گروهها، ابزار سنجش نابرابر، نمونهگیری سوگیرانه و حمل تبعیض تاریخی به آینده.
پرسشهای متداول (FAQ)
۱) اگر جنسیت/نژاد را حذف کنیم کافی است؟
خیر. Proxyها همان اثر را بازسازی میکنند (مثل کدپستی/نوع دستگاه). راهحل: شناسایی و مهار پروکسیها، کالیبراسیون درونگروهی و استفادهٔ آگاهانه از متغیرهای حساس در مرحلهٔ آموزش/اعتبارسنجی برای تصحیح نابرابری—با مستندسازی حقوقی.
۲) کدام متریک برای مسئلهٔ ما مناسبتر است؟
به هدف تصمیم بستگی دارد:
-
فرصت برابرِ دسترسی → DP
-
از دستندادن موارد واقعی (سلامت/ایمنی) → EO
-
توازن TPR/FPR (استخدام/ارزیابی مقرراتی) → EOdds
-
امتیاز ریسکِ قابل اعتماد (وام/بیمه) → Calibration
بهصورت عملی ترکیب دو یا سه متریک را بسنجید و مصالحه را مستند کنید.
۳) آیا آستانههای جداگانه برای گروهها عادلانهاند؟
میتواند باشد، اگر با مستندات شفاف، تحلیل اثر، و محدودیت زمانی/بازبینی دورهای اجرا شود. هدف، برابری در نتیجهٔ عادلانه (Opportunity/Errors) است، نه تبعیض معکوس. هر تغییر آستانه باید همراه AIA و بررسی حقوقی باشد.
۴) چگونه اعتراض کاربر را عملیاتی کنیم؟
-
مسیر «Explain & Appeal» در UI: دلیل تصمیم، اسناد موردنیاز، مهلت، کانال ارتباط.
-
SLA پاسخ (مثلاً ۷۲ ساعت) + پیگیری وضعیت.
-
ثبت نتایج اعتراضها به تفکیک گروه برای بهبود مدل.
-
انتشار Model/Data Cards و Change Log (dateModified) برای اعتمادپذیری.
جمعبندی و گام بعدی
خلاصهٔ اجرایی برای بستن حلقهٔ «تعریف تا عمل» و پاسخ عملی به سؤال «سوگیری الگوریتمی چیست».
۵ نکتهٔ کلیدی:
-
بدون تعریف دقیق هدف تصمیم و همراستاسازی آن با هدف پیشبینی، عدالت سنجشپذیر نیست.
-
سوگیری بیشتر از داده میآید؛ پوشش نمایندگی و مهار Proxyها را قبل از آموزش حل کنید.
-
عدالت یک عدد نیست؛ ترکیبی از DP/EO/EOdds/Calibration با گزارش گروهبهگروه لازم است.
-
سوگیری پس از استقرار هم رخ میدهد؛ Drift/Function Creep را با پایش و ممیزی دورهای کنترل کنید.
-
اعتماد از شفافیت میآید: AIA، Model/Data Cards، مسیر اعتراض، و Change Log.





